TAP ‒ Open Source Platform for building Big Data and Machine Learning applications
Trusted Analytics Platform (TAP) tutorial is designed to walk you through the most relevant features and functionalities of the TAP platform. Nowadays, as we witness a surge of open source frameworks it has become difficult and time consuming to combine many of them together. In order to leverage, latest Big Data and Analytics tools, TAP platform easily integrates well known open source products with each other i.e. Kafka, Spark, HDFS, Hive and other Cloudera Hadoop components. As there are unlimited permutations of scenarios that users need, the TAP’s flexibility enables to bind many services into one custom workflow. During the tutorial, we are going to start from an Overview session where you will have a chance to better understand what the TAP is. The following session will cover application development and the process of publishing it on the platform. This is a good exercise for Software Developers to get some familiarity with integration and deployment aspects of Big Data projects on TAP. Next two sessions will focus on Analytics and Machine Learning side in order to ultimately better understand Data Science workflow using TAP.
The tutorial will consist of 4, 90-minute-long parts presented below.
Please note:
- limited availability – first come first served,
- all participants should bring their Laptops (with: java 8, maven, favourite java IDE, web browser, git installed) to the session.
Part I – Trusted Analytics Platform Overview
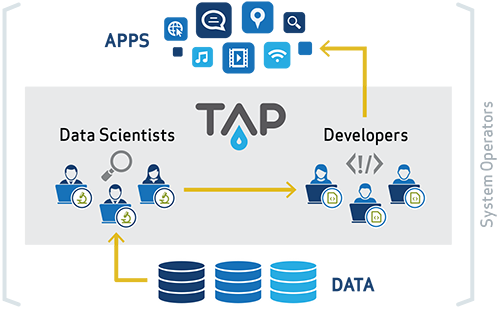
In first part of the training we will deliver generic information about Trusted Analytics Platform (TAP) architectural components, major technologies constituting fundamentals of the platform and how they address the goals of the platform.
Part II – Application development & deployment on TAP
As another step in the tutorial we will get familiar with developing and deploying applications on TAP. We will write sample application in Java that will process data stored on HDFS. A focus will be placed on how to get access to Hadoop components and configure, deploy and scale application on TAP.
Part III – ETL + Data Science Use Case
Part III will cover enterprise class batch data science work. We will connect to a RDBMS database and first download the data to the HDFS system. Next, the data transformation, training and testing will take place. Ultimately, predictions will be send back to the Data Warehouse system. This is a standard enterprise use case where the data goes back to some Business Intelligence class type system.
Part IV – Streaming Use Case
In the following session an emphasis will be put on the streaming analytics area. The training model will be built in the batch mode but predictions will be provided in the streaming fashion.
Lecturers
 Tomasz Rutowski – TAP Architect in the Analytics domain with Data Science background primarily in telecommunication industry. His experience encompasses Internet of Things project, Wireless Network as well as customer and marketing analytics initiatives. Currently, deep learning is the area that he explores in order to better integrate algorithms from this domain with TAP platform.
Tomasz Rutowski – TAP Architect in the Analytics domain with Data Science background primarily in telecommunication industry. His experience encompasses Internet of Things project, Wireless Network as well as customer and marketing analytics initiatives. Currently, deep learning is the area that he explores in order to better integrate algorithms from this domain with TAP platform.

Dominika Puzio – Java developer and enthusiast. For the last 9 years she worked as a software developer, software architect, team leader and technical project manager as well as a university lecturer. Currently works on TAP platform at Intel.
When not shipping code for work she speaks at local JUG, conducts trainings and consults search solutions based on technologies around Apache Lucene.

Grzegorz Świrski – Cloud Software Engineer at Intel, developer in Trusted Analytics Platform with educational background in control engineering and information technology. Currently focusing on applications layer development. His preferred domains of work include clean code development in Java/Spring and Python.